ネイティブな lipsync
Kling 3.0 Omni に内蔵。別工程なしで口の動きが音声にぴたりと合います。
どんな顔も、あなたの音声に同期。セリフも、歌も、会話も。
Kling 3.0 Omni に内蔵。別工程なしで口の動きが音声にぴたりと合います。
ナレーション、ボーカルトラック、台本のセリフから口元を動かせます。
生成したキャラはもちろん、FacePass で事前に認可した実在の顔も使えます。
一度の生成で最大 6 ショットにわたり、キャラのセリフを同期させたまま保てます。
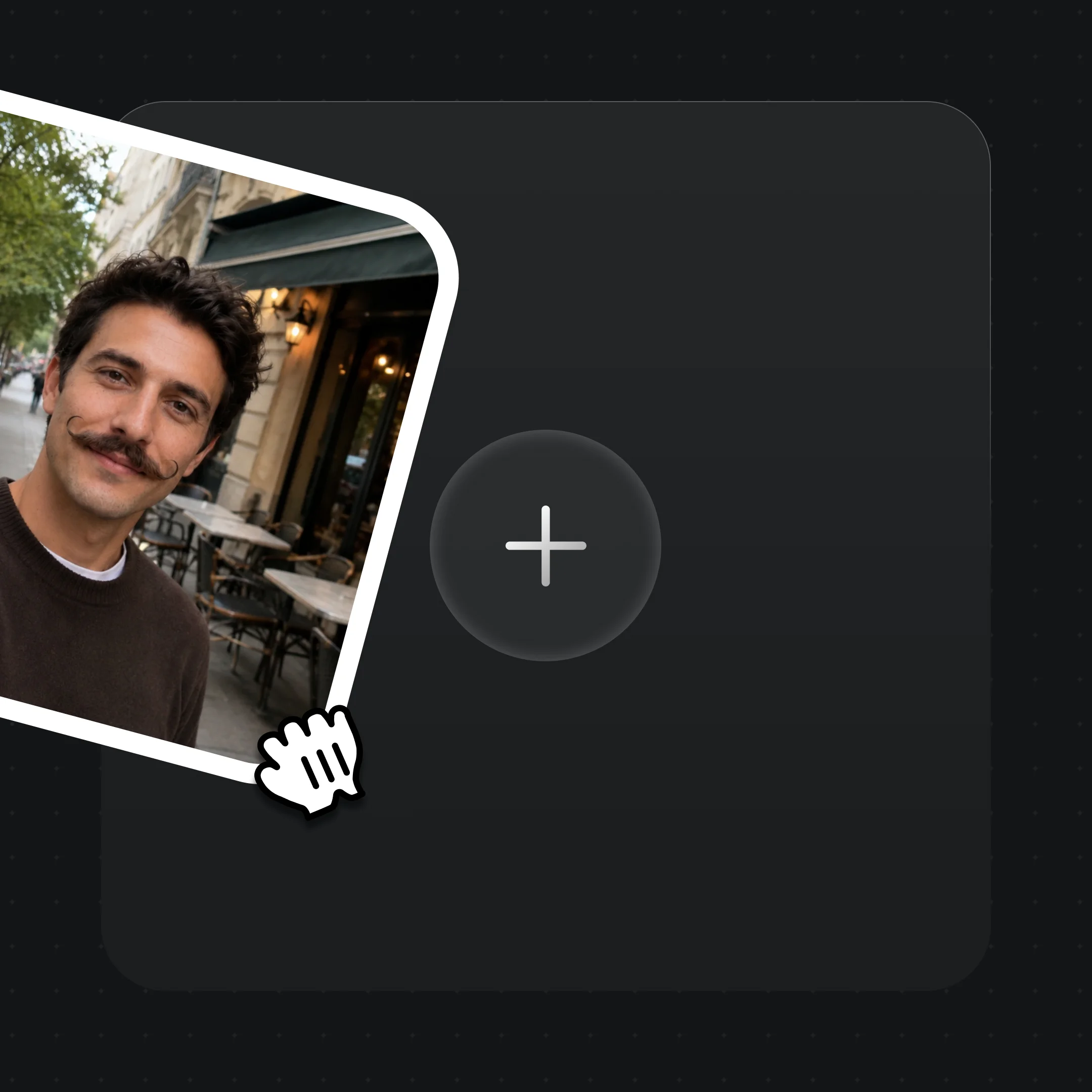
生成キャラ、または FacePass で認可済みの写真を Canvas にドロップします。
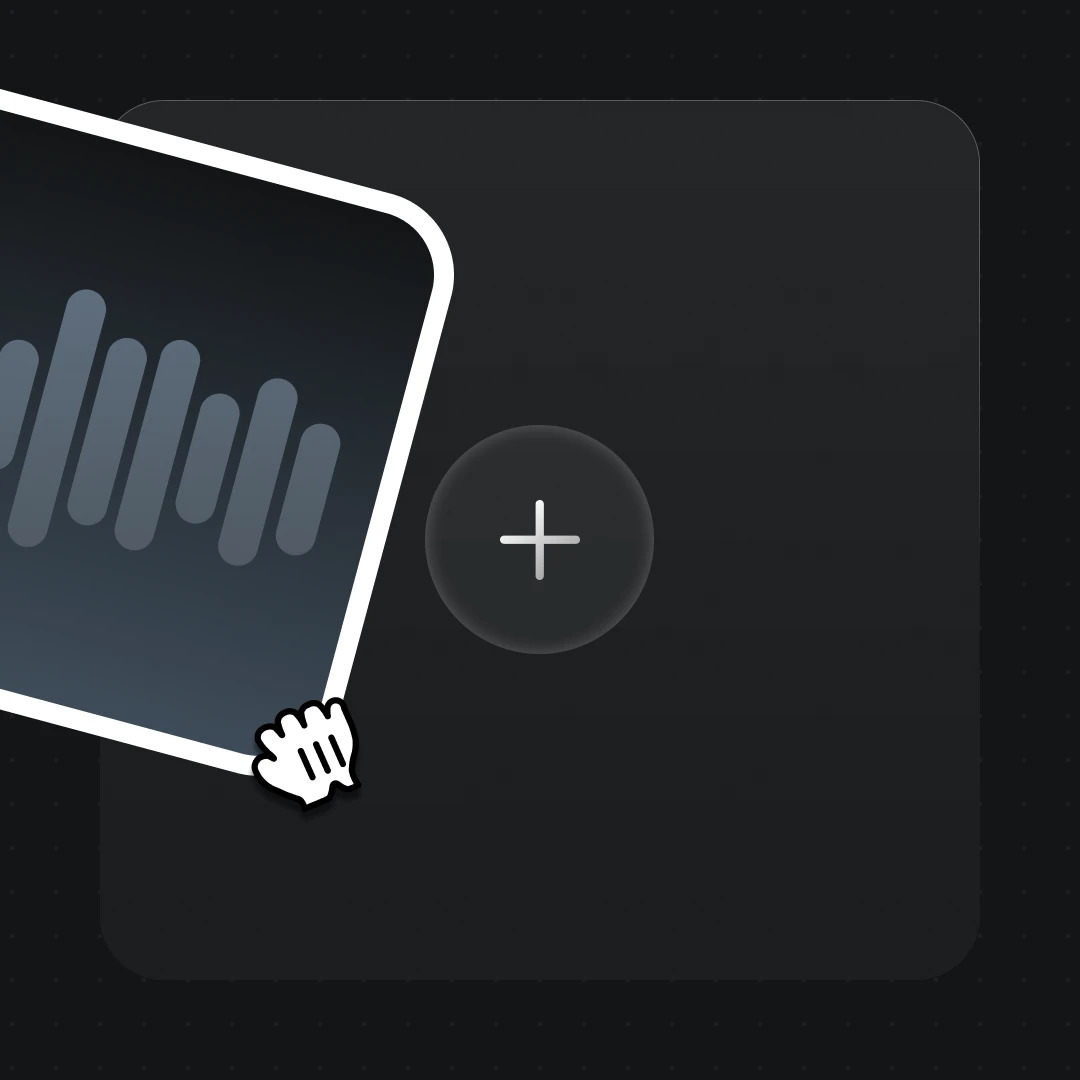
ナレーションやボーカルトラックをアップロード、またはキャラに喋らせるセリフを入力します。
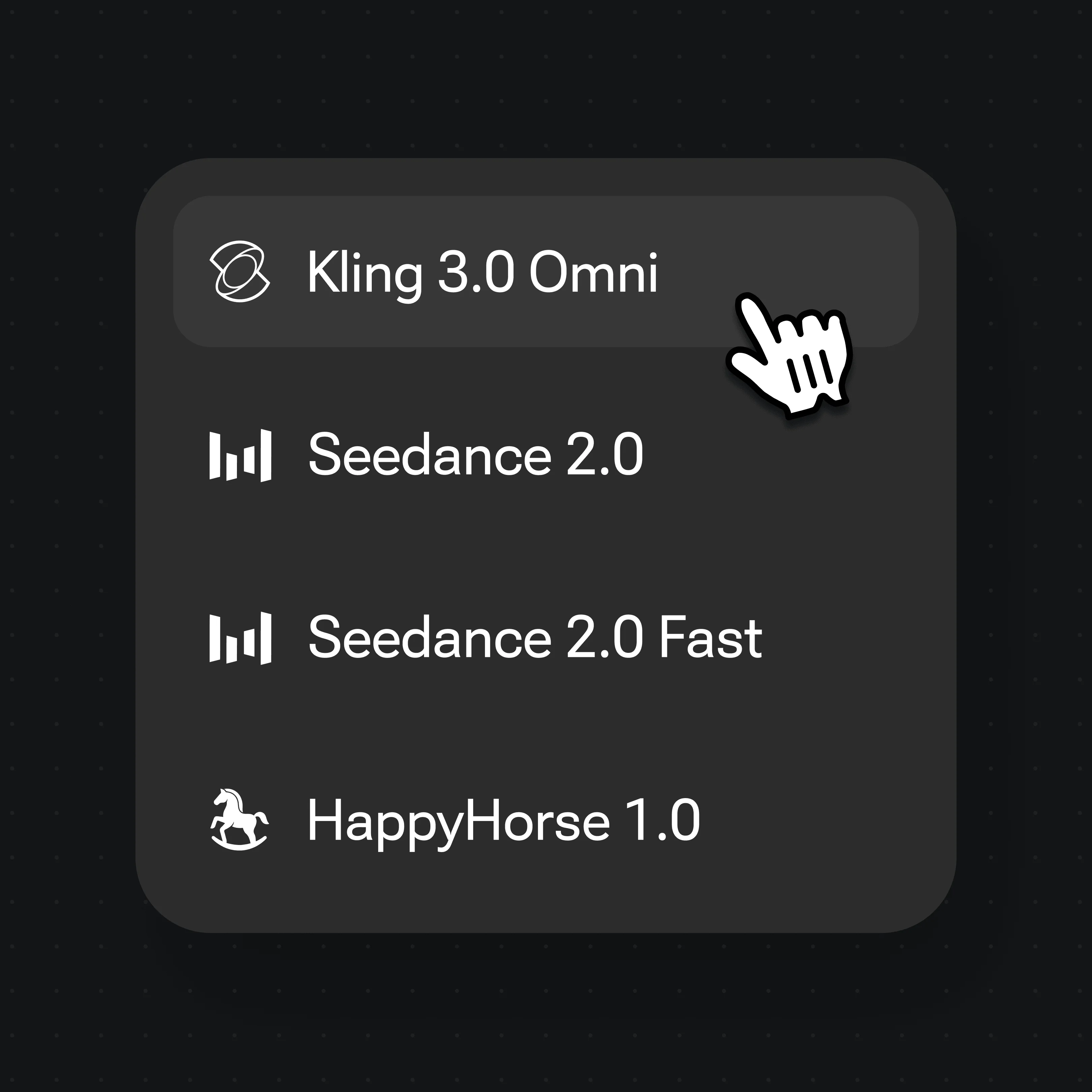
モデルセレクターで Kling 3.0 Omni を選び、Generate を押すだけ——口元が音声に同期します。
スポークスパーソンが台本のセリフを読み上げ、口元はナレーションにぴたり一致。
宙に浮いた顔だけではなく、映画的なショットの中でキャラがそのまま喋ります。
オリジナルキャラに声を与え、セリフを同期したまま語らせましょう。
凝った衣装やシーン転換でも、クローズアップ以外でリップシンクを保ちます。
1つのRoiseプランで、口パク・FacePass・全動画モデルをアンロック。
AI リップシンクは、顔の口の動きを指定した音声トラック——セリフ、歌、会話——に合わせてアニメーションさせる技術です。Renoise では Kling 3.0 Omni モデルにネイティブ搭載されているため、別の後処理工程なしにキャラを同期させて喋らせられます。
はい。lipsync は Renoise Canvas のモデルの一つ、Kling 3.0 Omni に内蔵されています。顔と音声トラックを追加し、Kling 3.0 Omni を選べば、生成キャラが同期して喋ります。
使用許可があり、FacePass で事前に認可した顔に限ります。多くのモデルは判別可能な実在の顔をブロックしますが、FacePass が承認された経路です。著名人・公人・未成年は不可です。
ナレーション、ボーカルトラック、またはキャラに喋らせるために入力した台本のセリフが使えます。モデルが音声を口の形にマッピングするので、トラックが話す内容に合わせて口元が動きます。
はい。ボーカルトラックから顔を動かせば、キャラが同期して歌います。AI ミュージックビデオのワークフローと組み合わせれば、Canvas 上でパフォーマンス映像を一本仕上げられます。
Kling 3.0 Omni の 1 クリップは 3〜15 秒です。より長い喋りや歌の映像にしたい場合は、同期した複数のクリップを Canvas のタイムラインでつなぎ合わせてください。
いいえ。リップシンク動画は動画モデルで生成されるため、720p または 1080p での出力です。4K は画像モデル——Nano Banana Pro と GPT Image 2——で利用でき、動画では利用できません。
Kuaishou による Kling 3.0 Omni で、lipsync をネイティブに備えています。Renoise はこれを Seedance 2.0 などのモデルと並べて統合しており、動画モデルを自社で学習させているわけではありません。
