Lipsync nativo
Integrado ao Kling 3.0 Omni, então a boca acompanha o áudio sem etapa separada.
Sincronize qualquer rosto com o seu áudio — fala, canto ou diálogo.
Integrado ao Kling 3.0 Omni, então a boca acompanha o áudio sem etapa separada.
Comande a boca a partir de uma narração, uma faixa vocal ou um diálogo roteirizado.
Um personagem gerado ou um rosto real que você liberou antes pelo FacePass.
Mantenha o personagem falando em sincronia por até seis cenas em uma única geração.
Solte um personagem gerado ou uma foto liberada pelo FacePass no Canvas.
Suba uma narração ou faixa vocal, ou digite uma fala para o personagem dizer.
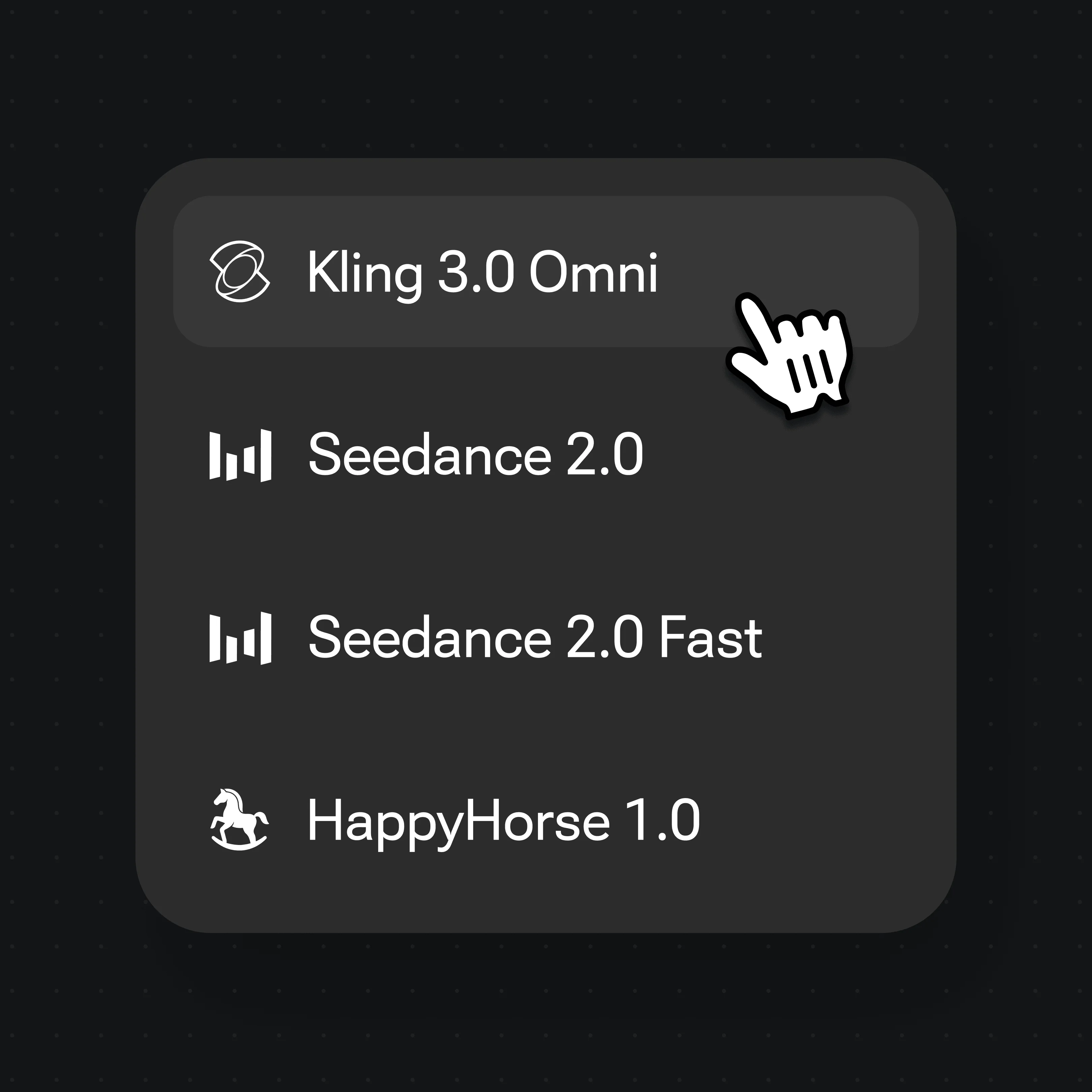
Selecione o Kling 3.0 Omni no seletor de modelos e clique em Gerar — a boca sincroniza com o áudio.
Um porta-voz diz uma fala roteirizada, com a boca sincronizada à narração.
Um personagem fala dentro de uma cena cinematográfica completa, não um rosto solto no ar.
Dê voz a um personagem original e veja-o dizer as falas em sincronia.
O lipsync se mantém mesmo com figurino pesado e troca de cena, não só em close-ups.
Desbloqueie lip sync, FacePass e todos os modelos de vídeo em um plano Renoise.
Lipsync nativo, rostos do FacePass e mais modelos em um só Canvas.
A sincronização labial com IA anima um rosto para que a boca acompanhe uma faixa de áudio — fala, canto ou diálogo. No Renoise ela é nativa do modelo Kling 3.0 Omni, então um personagem pode falar em sincronia sem uma etapa de pós-produção separada.
Sim. O lipsync é integrado ao Kling 3.0 Omni, um dos modelos do Renoise Canvas. Adicione um rosto e uma faixa de áudio, escolha o Kling 3.0 Omni e o personagem gerado fala em sincronia.
Apenas um rosto que você está autorizado a usar, liberado antes pelo FacePass. A maioria dos modelos bloqueia rostos reais detectáveis; o FacePass é o caminho aprovado. Nada de celebridades, figuras públicas ou menores de idade.
Uma narração, uma faixa vocal ou um diálogo roteirizado que você digita para o personagem dizer. O modelo mapeia o áudio para os movimentos da boca, então os lábios acompanham o que a faixa está dizendo.
Sim. Comande o rosto a partir de uma faixa vocal e o personagem canta em sincronia. Combine com o fluxo de vídeo musical com IA para montar um clipe de performance completo no Canvas.
Cada clipe do Kling 3.0 Omni dura de 3 a 15 segundos. Para uma cena falada ou cantada mais longa, junte vários clipes sincronizados na Timeline do Canvas.
Não. O vídeo de lip sync sai em 720p ou 1080p, pois roda em um modelo de vídeo. O 4K está disponível para os modelos de imagem — Nano Banana Pro e GPT Image 2 — não para vídeo.
O Kling 3.0 Omni, da Kuaishou, que tem lipsync nativo. O Renoise o integra junto ao Seedance 2.0 e a outros modelos — ele não treina modelos de vídeo por conta própria.
