本物らしい人物
生成したポートレートや参照から始め、その見た目を動きの中へ引き継ぎます。

リアルなAI人間を作り、カメラの前で話させ、動かしましょう。
まず人物を画像として生成します——見た目を説明するか、ポートレートを選ぶか——そのフレームをKling 3.0 OmniまたはSeedance 2.0で動画にします。Kling 3.0 Omniはネイティブのlipsyncを備え、人間が話せます。Seedance 2.0はオーディオネイティブな動きを出力します。実在の人物の場合は、まずFacePassでその顔を認証してください。
これは動画生成であり、AIテキストのhumanizerではありません。 AI talking photoを見る
RenoiseでのAI人間動画はこんな感じです。
生成したポートレートや参照から始め、その見た目を動きの中へ引き継ぎます。
Kling 3.0 Omniはネイティブのlipsyncを備え、AI人間がプレゼンし話せます。
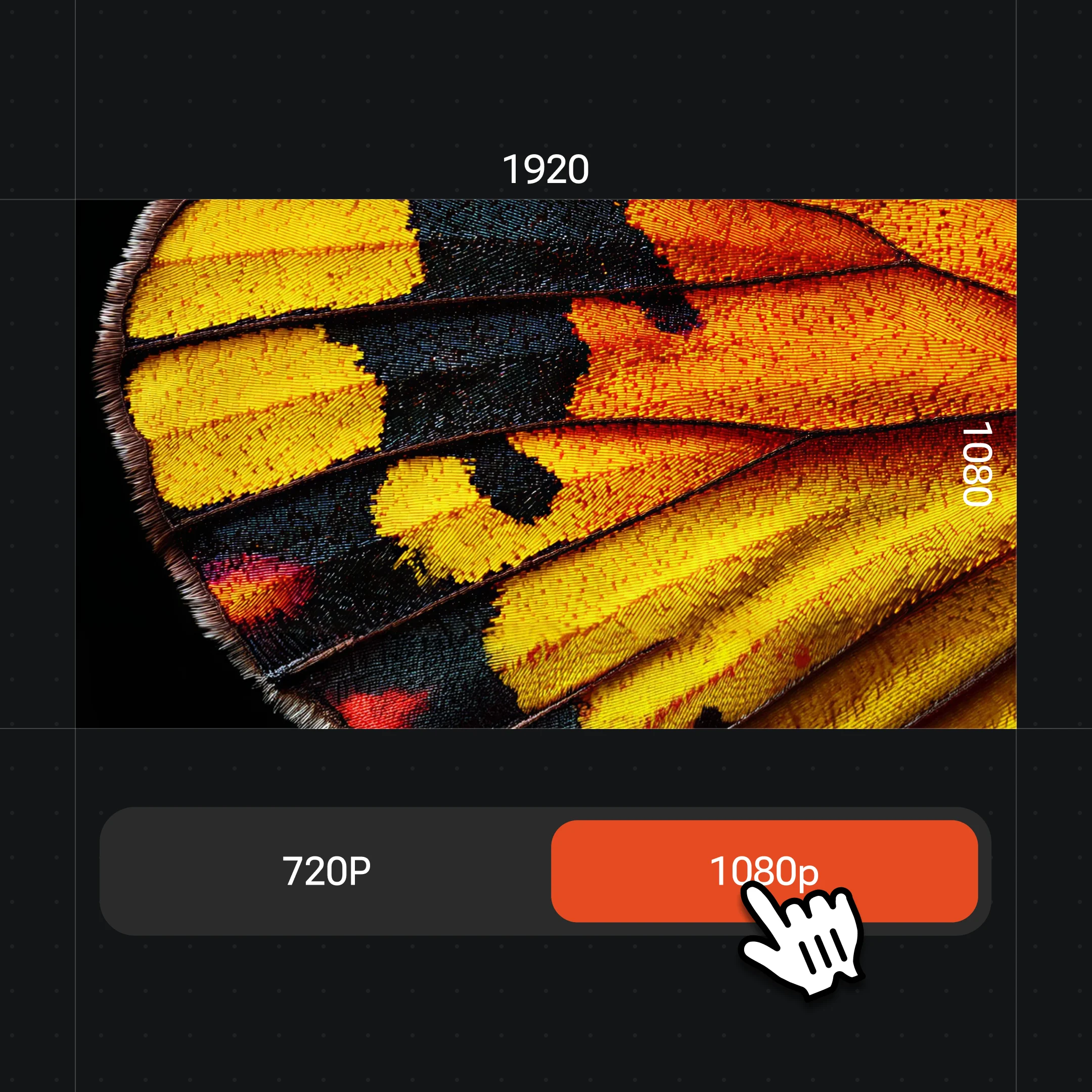
720pまたは1080pで3〜15秒のクリップ——静止アバターではなく、実際に動く人物です。
FacePassが、あなたが所有する、または同意を得た肖像を、動画に入る前に認証します。
生成したポートレートから、画面の中で動き話す人物まで。
欲しい人間を説明してポートレートを生成し、解像度メニューで1K〜4Kを選んで鮮明なソースフレームを作ります。
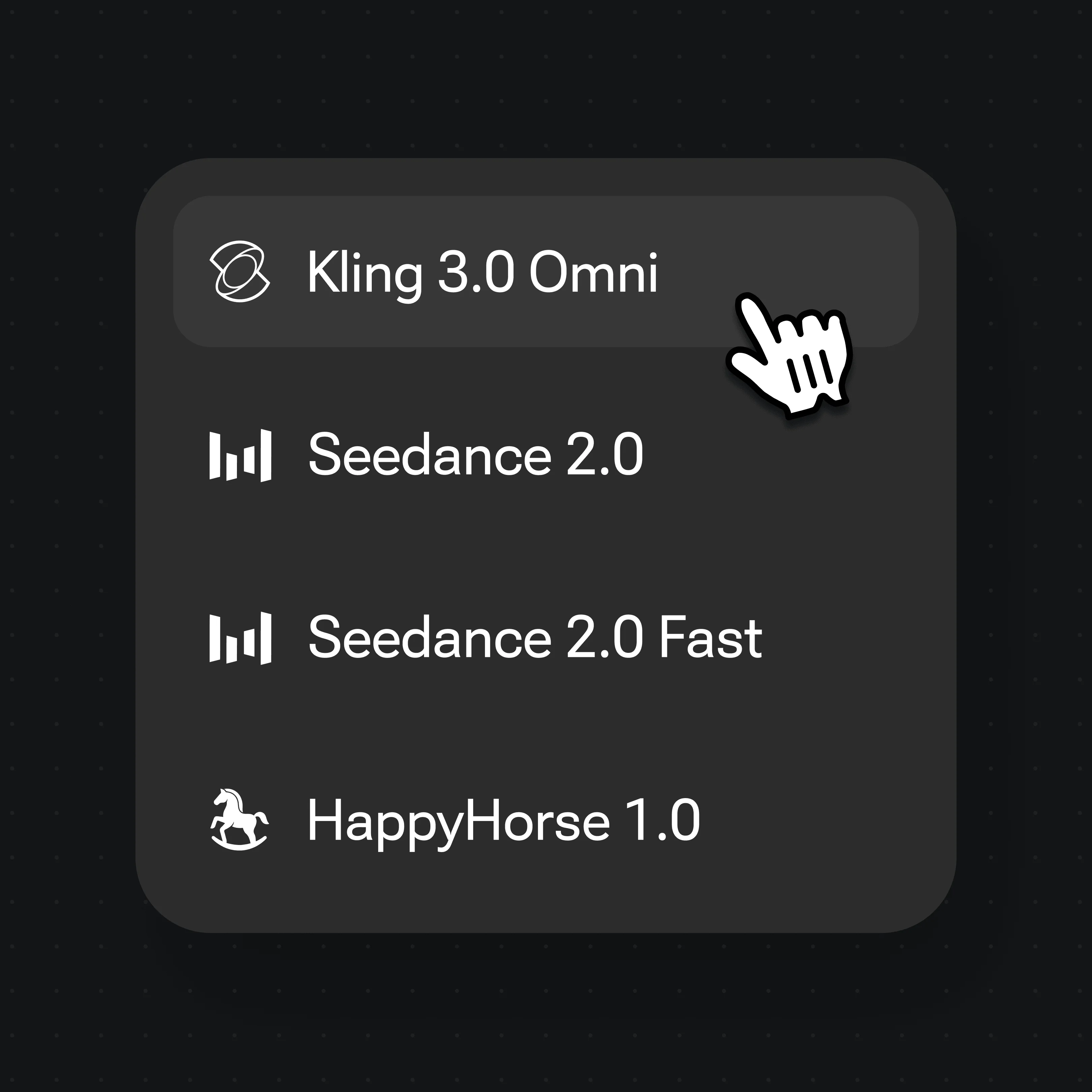
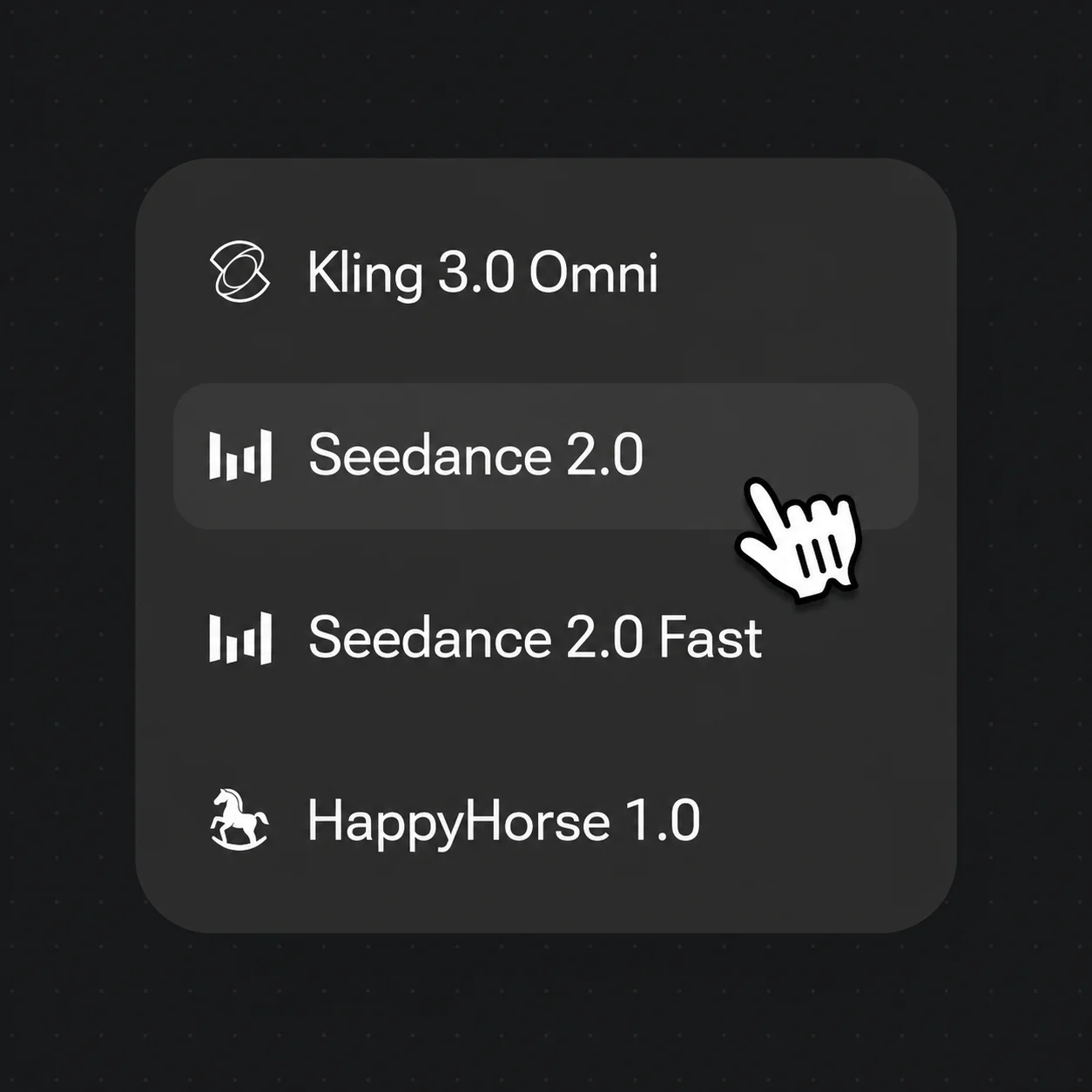
モデルメニューを開き、話す人間ならKling 3.0 Omni、オーディオネイティブでシネマティックな動きならSeedance 2.0を選びます。
ポートレートをimage-to-videoし、lipsync用のセリフを加え、Canvas Timelineでクリップをつないで長い作品にします。
Renoiseで生成した人物のフレーム——フレームを動画に送る前の、出発点となるデジタルヒューマンです。

カメラに向かって話すトーキングヘッドのプレゼンター。

シーンの中を動き回るプレゼンター。

Kling 3.0 Omniのネイティブlip-sync。

1つのシーンに複数のオリジナル人物を起用。
どちらも同じRenoise Canvasにあります——ショットごとに選びましょう。話すマルチショットの人間ならKling 3.0 Omni、オーディオネイティブでシネマティックな動きならSeedance 2.0。
| AI人間動画向け | Kling 3.0 Omni (Recommended) | Seedance 2.0 |
|---|---|---|
| 得意分野 | 話すプレゼンター、マルチショット | オーディオネイティブ、シネマティック |
| ネイティブlipsync | ✓ | — |
| マルチサブジェクトの一貫性 | ✓ | 良好 |
| FacePass対応 | ✓ | ✓ |
| クリップの長さ | 3〜15秒(参照動画ありで≤10秒) | 4〜15秒、さらにFast mode |
| 解像度 | 720p / 1080p | 720p / 1080p |
この分野で「AI人間」というと、たいてい2つのどちらかを指します。デジタルヒューマンは、ゼロから生成する人物です——顔・年齢・スタイリング・ライティングを説明してフォトリアルなポートレートを得て、そのフレームを動画として動かします。AIアバターは、台本を当てはめる出来合いのトーキングヘッドで、速いものの、顔はあなたが作ったものではなくテンプレートです。Renoiseはデジタルヒューマン側に立っています:あなたが人物を生成するので、見た目はストックのプレゼンターではなくあなたのものになり、構図・動き・シーンを完全にコントロールできます。
実際のワークフローは「生成してから動かす」です。まず画像モデルで人物と解像度(1K〜4K)を固め、そのフレームを動画モデルでimage-to-videoします。人間が話す必要があるときはKling 3.0 Omni——ネイティブのlipsyncが発話を口に同期させ——カットをまたいでマルチサブジェクトの一貫性を保ちます。人間がカメラに向かって話すのではなくシーンの中を動くときは、オーディオネイティブでシネマティックな動きのSeedance 2.0が選択肢です。
人間が実在の人物の場合、ルールが変わります。検出可能な実在の顔は、承認が必要な肖像として扱われるため、動画に入る前にFacePassを通す必要があります——あなたが所有する顔か、書面で同意を得た顔だけです。完全に架空の、生成された人間に認証は不要です。公的な人物、有名人、未成年は決して許可されません。
AI人間動画はいくつかの要素に支えられています——動画モデル、アイデンティティ認証、そしてCanvasです。
ネイティブのlipsyncとマルチサブジェクトの一貫性で、人間がカットをまたいでプレゼンできます。
1つのプロンプトから、オーディオネイティブでマルチモーダル参照の動画を最大1080pで。
あなたが所有する、または同意を得た実在の肖像を、動画に入る前に認証します。
人間のクリップをつないで、カットとトランジション付きの長いプレゼンター動画にします。
1つのプランでFacePass、Kling 3.0 Omni、Seedance 2.0、その他すべてのモデルが使えます。
人物のポートレートを生成し、そのフレームをKling 3.0 OmniまたはSeedance 2.0でimage-to-videoします。Kling 3.0 Omniはネイティブのlipsyncを備え、人間が話せます。Seedance 2.0はオーディオネイティブな動きを出力します。長い作品にするにはCanvas Timelineでクリップをつなぎます。
いいえ。このページは、リアルなAI人間を動画で生成すること——カメラの前に置けるデジタルヒューマン——についてです。AIテキストのhumanizerでも、AIが書いた文章を書き直すツールでもありません。ここでの「人間」は、あなたが生成してアニメ化する人物です。
あなたが使う権限を持つ顔だけです——自分の顔、または書面で同意を得た顔。実在の顔はまずFacePassを通す必要があり、検出可能な実在の顔は通過するまでブロックされます。完全に架空の、生成された人間に認証は不要です。公的な人物、有名人、未成年は許可されません。
人間が話す必要があるときはKling 3.0 Omni——ネイティブのlipsyncが発話を同期します——またはマルチショットの一貫性に。オーディオネイティブでシネマティックな動きにはSeedance 2.0。どちらも同じCanvasでFacePassに対応するので、ショットごとに切り替えられます。
はい、Kling 3.0 Omniで。ネイティブのlipsyncが発話されたセリフを口に同期させるので、生成したプレゼンターが台本を話せます。プロンプトにセリフを加えると、モデルがそれに合わせて顔をアニメ化します。
フォトリアルなポートレートはよく保たれ、同じソース画像を参照すればクリップ間で見た目が保たれます——ただし一貫性はモデルの強い挙動であって保証ではなく、顔は依然として漂うことがあります。実在の肖像については、FacePassの認証はこれとは別の手続きです。
Renoiseの動画モデルは720pまたは1080pで出力します。4Kの枠はソースのポートレートに使う画像モデルにのみ適用され、動画自体には適用されません。SNSやショート動画への公開には1080pで生成しましょう。
