原生 lipsync
内置于 Kling 3.0 Omni,口型直接对上音频,无需单独一步处理。
让任意人脸跟着你的音频开口——说话、唱歌或对白都行。
内置于 Kling 3.0 Omni,口型直接对上音频,无需单独一步处理。
用配音、人声轨或写好的台词来驱动口型。
生成的角色,或先经 FacePass 授权过的真人脸都行。
一次生成里,让角色在最多六个镜头中持续同步开口。
把生成的角色,或一张经 FacePass 授权的照片拖进 Canvas。
上传配音或人声轨,或者直接输入一句话让角色念出来。
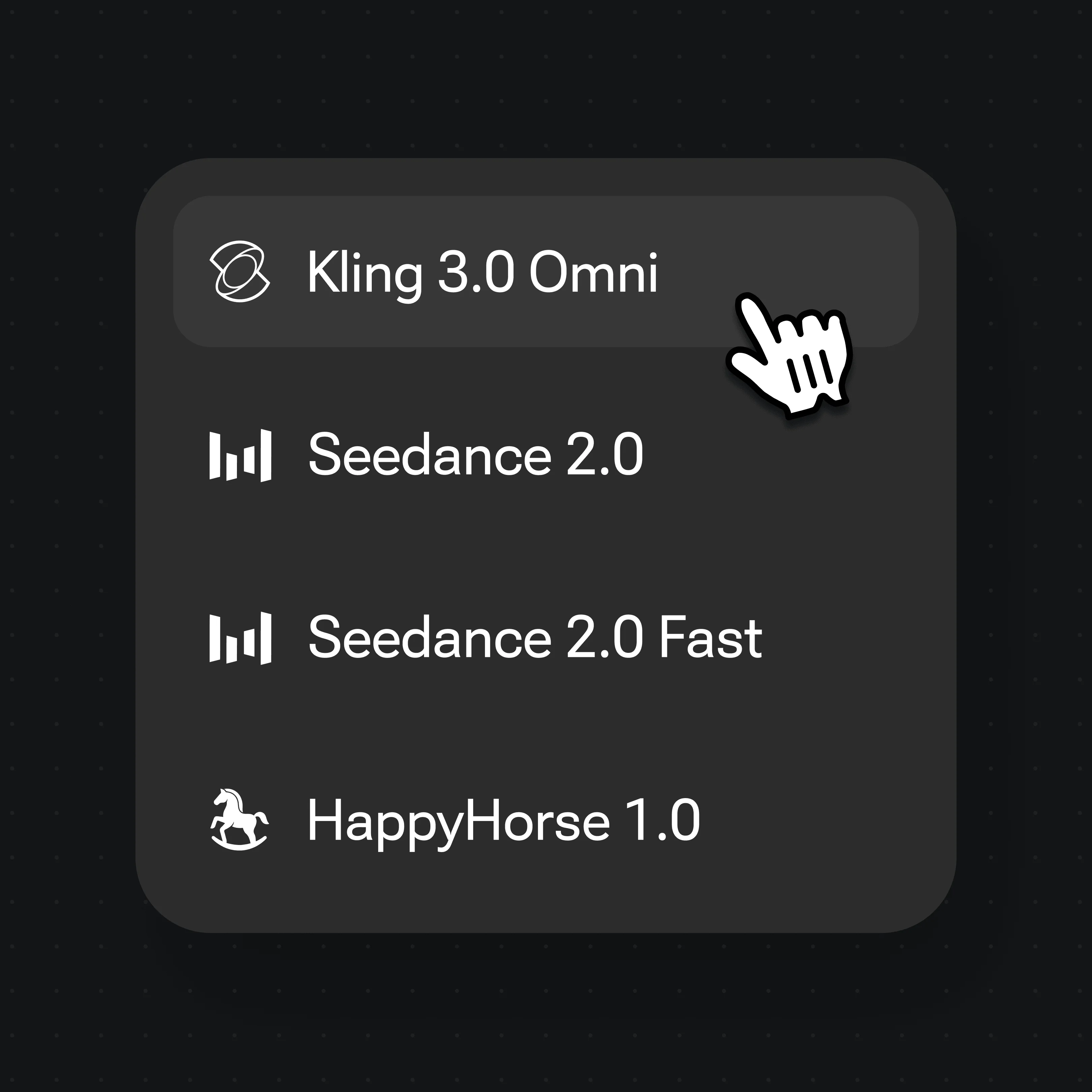
在模型选择器里选 Kling 3.0 Omni,点击生成——口型即跟音频同步。
主持人念出一段写好的台词,口型与配音严丝合缝。
角色在一个完整的电影级镜头里开口,而不是悬空的说话头像。
给一个原创角色配上声音,看它同步念出台词。
即便换上厚重戏服、切换场景,口型依旧同步,不只在特写里成立。
在一个 Renoise 套餐中解锁口型同步、FacePass 和所有视频模型。
AI 对口型会驱动一张人脸,让它的嘴型对上给定的音频——说话、唱歌或对白皆可。在 Renoise 里,它原生于 Kling 3.0 Omni 模型,所以角色能直接同步开口,不必再单独做后期。
支持。lipsync 内置于 Kling 3.0 Omni——Renoise Canvas 上的模型之一。放入人脸和音频轨,选 Kling 3.0 Omni,生成的角色就会同步开口。
只能用你有权使用、且先经 FacePass 授权过的人脸。多数模型会拦截可识别的真人脸,FacePass 是获批的合规路径。不涉及名人、公众人物或未成年人。
配音、人声轨,或你为角色输入的台词都行。模型会把音频映射成嘴型,所以口型会跟着音轨的内容走。
可以。用人声轨驱动人脸,角色就会同步开唱。配合 AI 音乐视频流程,就能在 Canvas 上做出一支完整的表演片段。
每个 Kling 3.0 Omni 片段时长 3 到 15 秒。想做更长的口播或演唱,就在 Canvas Timeline 上把多段同步片段拼接起来。
不能。对口型视频输出 720p 或 1080p,因为它跑在视频模型上。4K 仅图像模型可用——Nano Banana Pro 和 GPT Image 2——视频不支持。
Kling 3.0 Omni,由 Kuaishou 出品,自带原生 lipsync。Renoise 把它和 Seedance 2.0 等模型一同集成进来——本身并不训练视频模型。
