Pessoa verossímil
Comece de um retrato gerado ou de uma referência e leve essa aparência para o movimento.

Crie uma pessoa realista com IA e coloque-a diante das câmeras, falando e em movimento.
Primeiro gere a pessoa como imagem — descreva a aparência dela ou escolha um retrato — e depois transforme esse quadro em vídeo no Kling 3.0 Omni ou Seedance 2.0. O Kling 3.0 Omni adiciona lipsync nativo para que o humano possa falar; o Seedance 2.0 entrega movimento com áudio nativo. Para uma pessoa real, autorize o rosto dela com o FacePass primeiro.
Isto é geração de vídeo, não um humanizador de texto com IA. Ver foto que fala com IA
É assim que um vídeo de humano com IA fica no Renoise.
Comece de um retrato gerado ou de uma referência e leve essa aparência para o movimento.
O Kling 3.0 Omni adiciona lipsync nativo para que seu humano com IA apresente e fale.
Clipes de 3 a 15 s em 720p ou 1080p — não um avatar estático, mas uma pessoa que de fato se move.
O FacePass autoriza uma imagem que você possui ou para a qual tem consentimento antes que ela entre no vídeo.
De um retrato gerado a uma pessoa que se move e fala na tela.
Descreva o humano que você quer e gere um retrato, escolhendo de 1K a 4K no menu de resolução para um quadro de origem nítido.
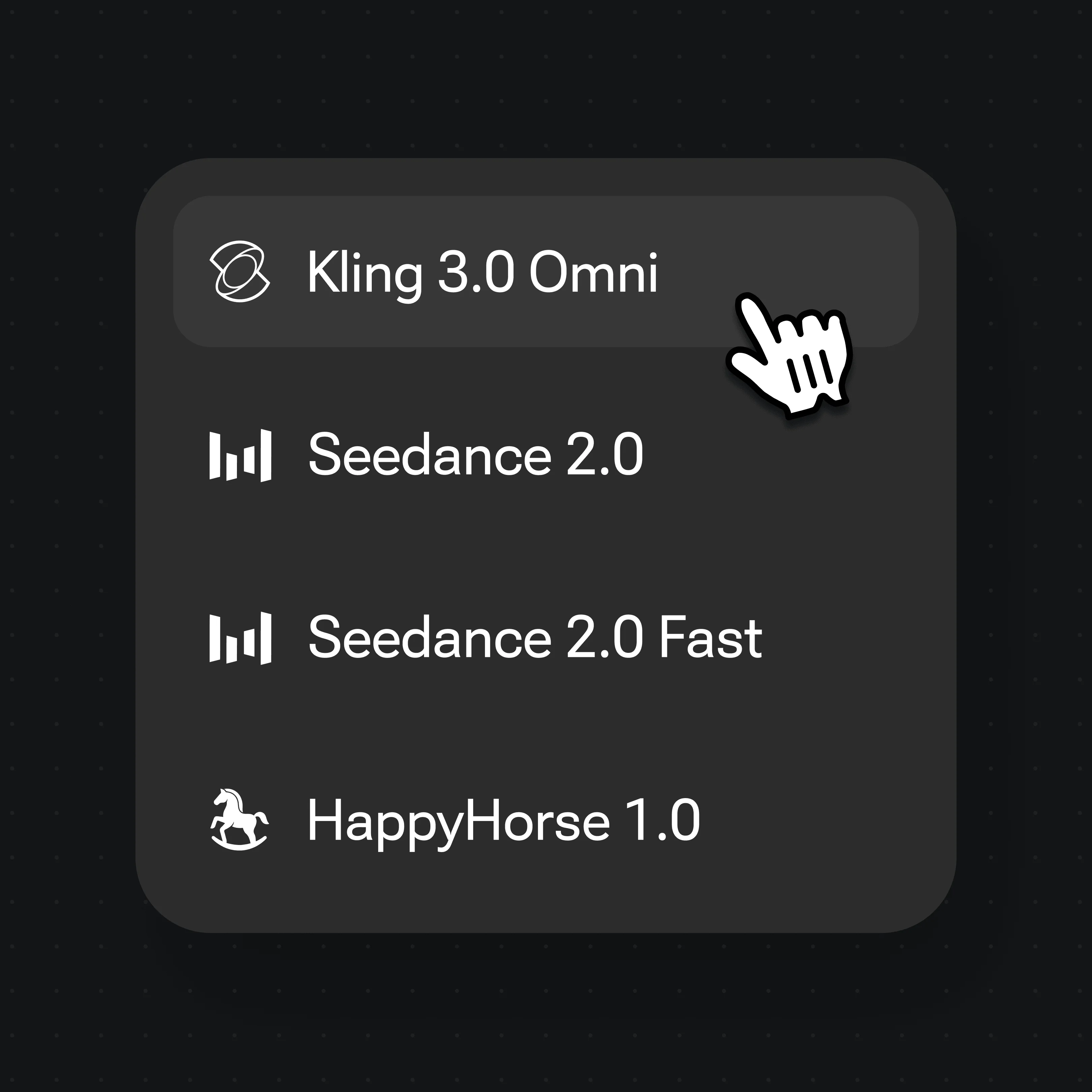
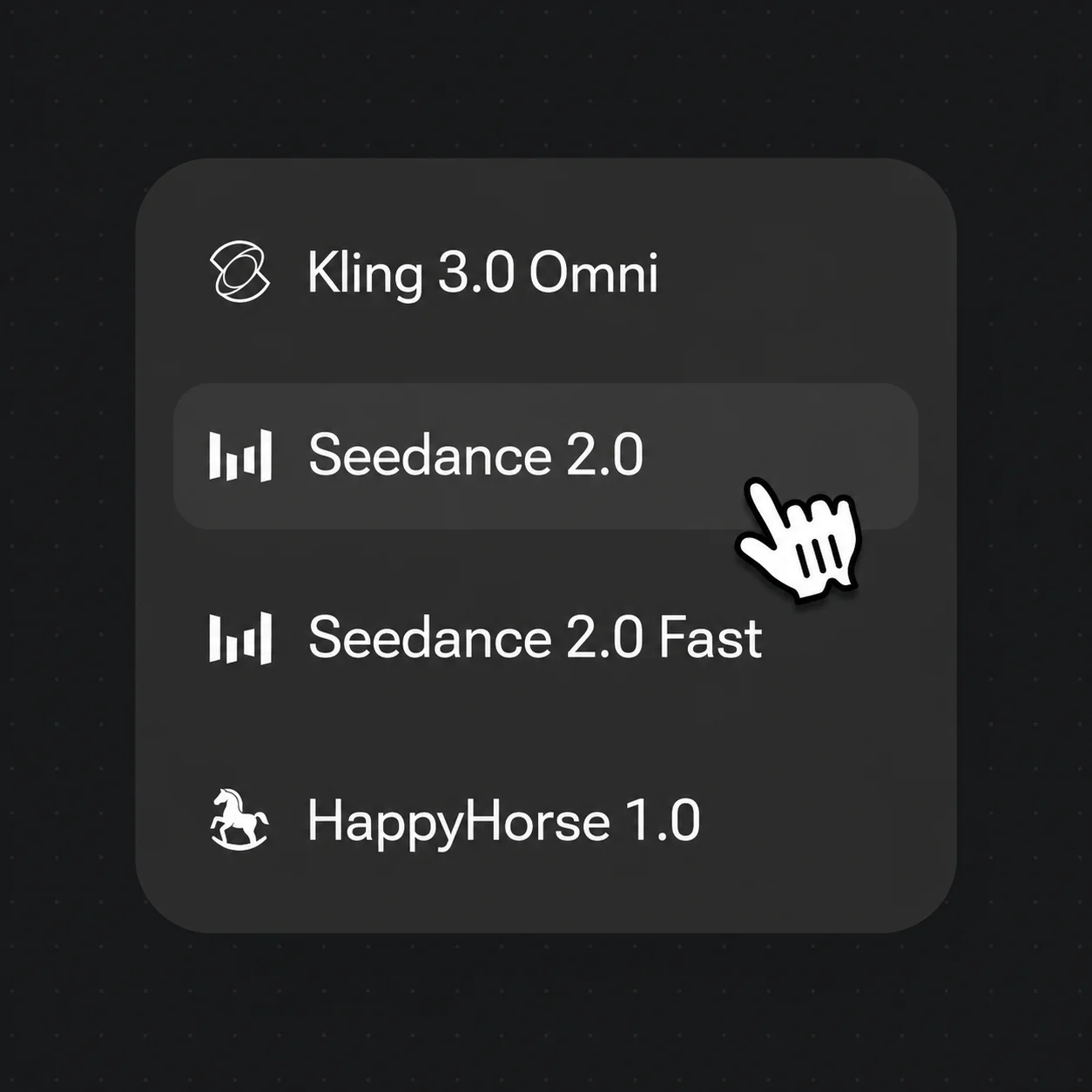
Abra o menu de modelos e escolha o Kling 3.0 Omni para um humano que fala, ou o Seedance 2.0 para movimento cinematográfico com áudio nativo.
Transforme o retrato em vídeo (image-to-video), adicione uma fala para o lipsync e junte os clipes na Canvas Timeline para uma peça mais longa.
Quadros de pessoas geradas no Renoise — os humanos digitais dos quais você parte antes de enviar um quadro para vídeo.

Um apresentador em close falando para a câmera.

Um apresentador se movendo por uma cena.

Lip-sync nativo no Kling 3.0 Omni.

Coloque várias pessoas originais em uma só cena.
Ambos vivem no mesmo Canvas do Renoise — escolha por tomada. Kling 3.0 Omni para um humano que fala e multitomadas; Seedance 2.0 para movimento cinematográfico com áudio nativo.
| Para vídeo de humano com IA | Kling 3.0 Omni (Recommended) | Seedance 2.0 |
|---|---|---|
| Ideal para | Apresentador que fala, multitomadas | Áudio nativo, cinematográfico |
| Lipsync nativo | ✓ | — |
| Consistência multissujeito | ✓ | Bom |
| Funciona com FacePass | ✓ | ✓ |
| Duração do clipe | 3–15 s (≤10 s com vídeo de referência) | 4–15 s, além do modo Fast |
| Resolução | 720p / 1080p | 720p / 1080p |
Nesse universo, "humano com IA" costuma significar uma de duas coisas. Um humano digital é uma pessoa que você gera do zero — descreve um rosto, uma idade, um estilo e uma iluminação, obtém um retrato fotorrealista e depois dá vida a esse quadro como vídeo. Um avatar de IA é um apresentador pronto sobre o qual você aplica um roteiro: mais rápido, mas o rosto é um modelo, não um que você criou. O Renoise fica do lado do humano digital: você gera a pessoa, então a aparência é sua, e não a de um apresentador de banco de imagens, e você mantém controle total sobre enquadramento, movimento e cena.
O fluxo prático é gerar e depois animar. Comece com um modelo de imagem para travar a pessoa e a resolução (1K–4K) e depois transforme esse quadro em vídeo (image-to-video) com um modelo de vídeo. O Kling 3.0 Omni é a escolha quando o humano precisa falar — seu lipsync nativo sincroniza uma fala com a boca — e mantém a consistência multissujeito entre cortes. O Seedance 2.0 é a escolha para movimento cinematográfico com áudio nativo, quando o humano se desloca por uma cena em vez de se dirigir à câmera.
Quando o humano é uma pessoa real, a regra muda. Um rosto real detectável é tratado como uma imagem que precisa de autorização, então ele deve passar pelo FacePass — um rosto que você possui ou para o qual tem consentimento por escrito — antes de poder entrar no vídeo. Um humano totalmente fictício e gerado não precisa de autorização. Figuras públicas, celebridades e menores nunca são permitidos.
O vídeo de humano com IA se apoia em algumas coisas — os modelos de vídeo, a autorização de identidade e o Canvas.
Lipsync nativo e consistência multissujeito para que um humano possa apresentar ao longo de vários cortes.
Vídeo com áudio nativo e referência multimodal a partir de um único prompt, até 1080p.
Autoriza uma imagem real que você possui ou para a qual tem consentimento antes que ela entre no vídeo.
Junte clipes de humanos em um vídeo de apresentador mais longo, com cortes e transições.
Um único plano libera FacePass, Kling 3.0 Omni, Seedance 2.0 e todos os outros modelos.
Crie uma pessoa, adicione lipsync e exporte sem marca d’água nos planos pagos.
Gere um retrato da pessoa e depois transforme esse quadro em vídeo (image-to-video) no Kling 3.0 Omni ou Seedance 2.0. O Kling 3.0 Omni adiciona lipsync nativo para que o humano possa falar; o Seedance 2.0 entrega movimento com áudio nativo. Junte os clipes na Canvas Timeline para uma peça mais longa.
Não. Esta página é sobre gerar pessoas realistas com IA em vídeo — um humano digital que você pode colocar diante das câmeras. Não é um humanizador de texto com IA nem uma ferramenta para reescrever texto gerado por IA. O "humano" aqui é uma pessoa que você gera e anima.
Apenas um rosto que você esteja autorizado a usar — o seu, ou um com consentimento por escrito. Rostos reais precisam passar pelo FacePass primeiro, e rostos reais detectáveis ficam bloqueados até serem autorizados. Um humano totalmente fictício e gerado não precisa de autorização. Figuras públicas, celebridades e menores não são permitidos.
Kling 3.0 Omni quando o humano precisa falar — seu lipsync nativo sincroniza a fala — ou para consistência em multitomadas. Seedance 2.0 para movimento cinematográfico com áudio nativo. Ambos funcionam com o FacePass no mesmo Canvas, então você pode alternar por tomada.
Sim, no Kling 3.0 Omni. Seu lipsync nativo sincroniza uma fala com a boca para que um apresentador gerado possa entregar um roteiro. Adicione a fala ao prompt e o modelo anima o rosto para combinar com ela.
Retratos fotorrealistas se mantêm bem, e referenciar a mesma imagem de origem preserva a aparência entre os clipes — mas a consistência é um comportamento forte do modelo, não uma garantia, e os rostos ainda podem variar. Para uma imagem real, a autorização do FacePass é um processo à parte.
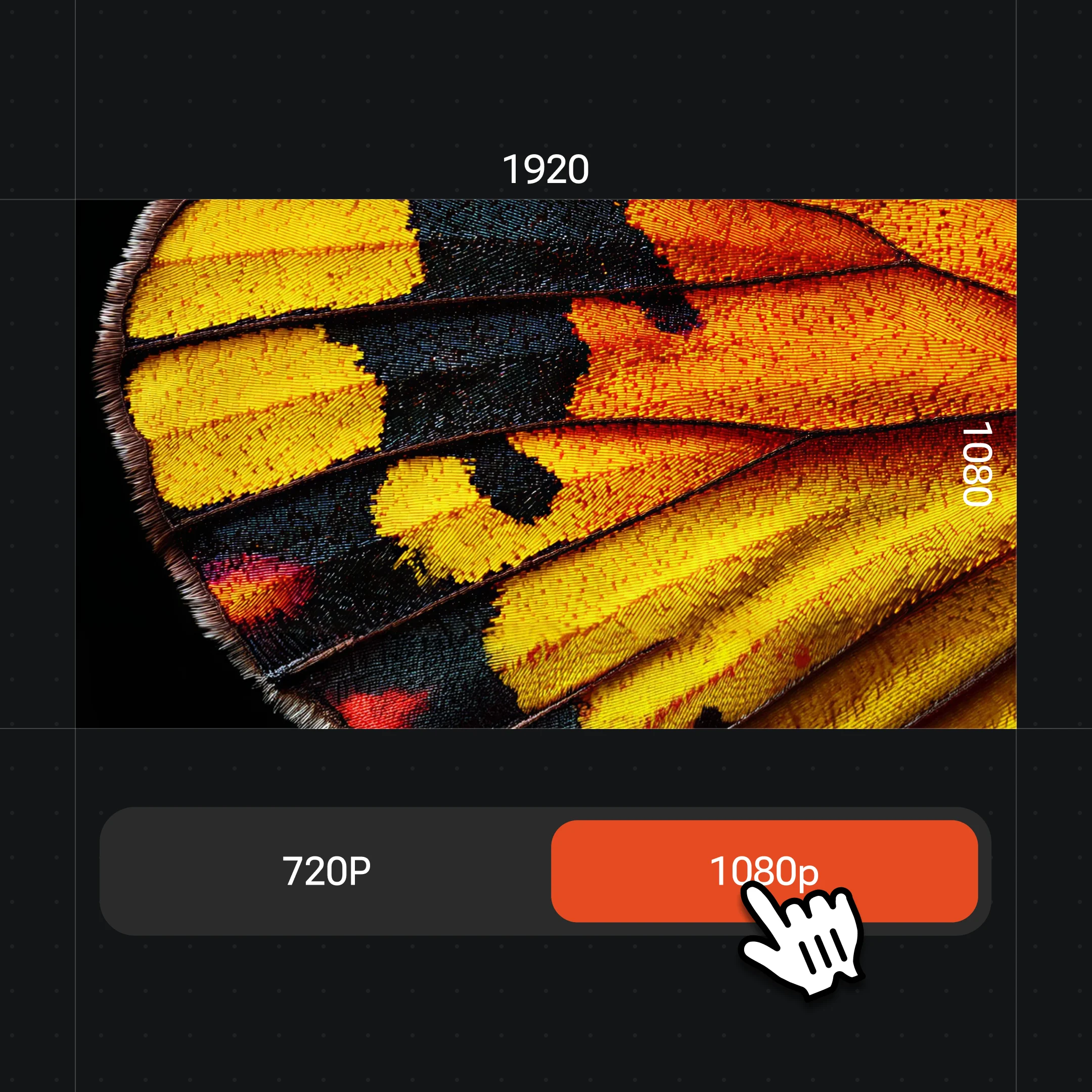
Os modelos de vídeo do Renoise geram em 720p ou 1080p. O nível 4K se aplica apenas aos modelos de imagem que você usa para o retrato de origem, não ao vídeo em si. Gere em 1080p para publicar em redes sociais ou plataformas de formato curto.
