逼真的人物
从生成的肖像或一张参考图出发,把这个样子带进动态画面。

造出一个逼真的 AI 人物,让他出镜、说话、动起来。
先把人物当成一张图生成出来——描述他的样子,或选一张肖像——再把这一帧用 Kling 3.0 Omni 或 Seedance 2.0 转成视频。Kling 3.0 Omni 自带 lipsync,能让数字人开口说话;Seedance 2.0 输出原生带音的动态。如果用的是真人,请先用 FacePass 把他的肖像授权过审。
这是视频生成,不是 AI 文本 humanizer。 查看 AI talking photo
AI 数字人视频在 Renoise 里是这个样子。
从生成的肖像或一张参考图出发,把这个样子带进动态画面。
Kling 3.0 Omni 自带 lipsync,让你的 AI 数字人能做主持、能开口。
3–15 秒的片段,720p 或 1080p——不是静态头像,而是真正会动的人。
FacePass 会先把你拥有或获得授权的肖像审过,才允许进入视频。
从一张生成的肖像,到一个在画面里说话、走动的人。
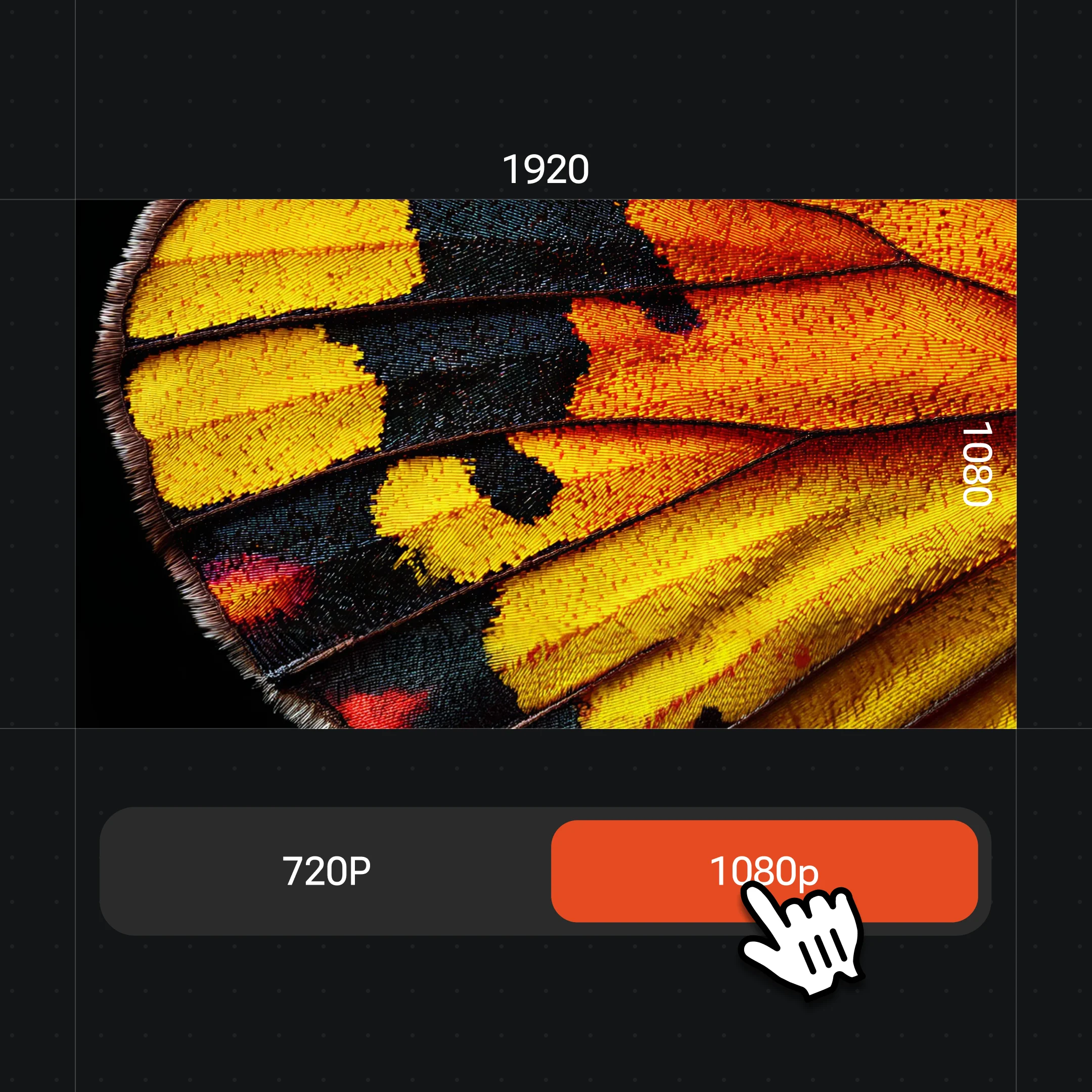
描述你想要的数字人并生成一张肖像,在分辨率菜单里选 1K–4K,得到一帧干净的源图。
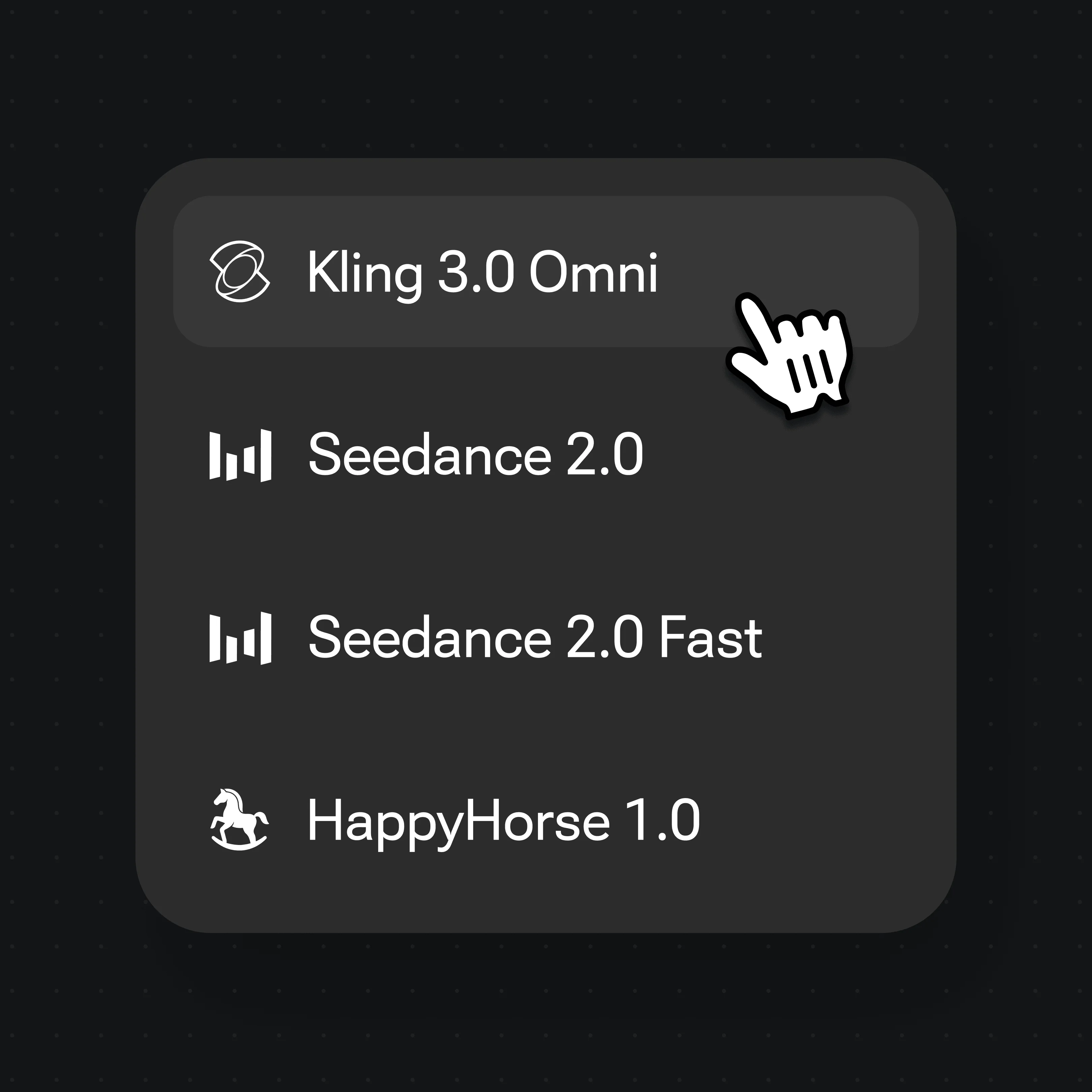
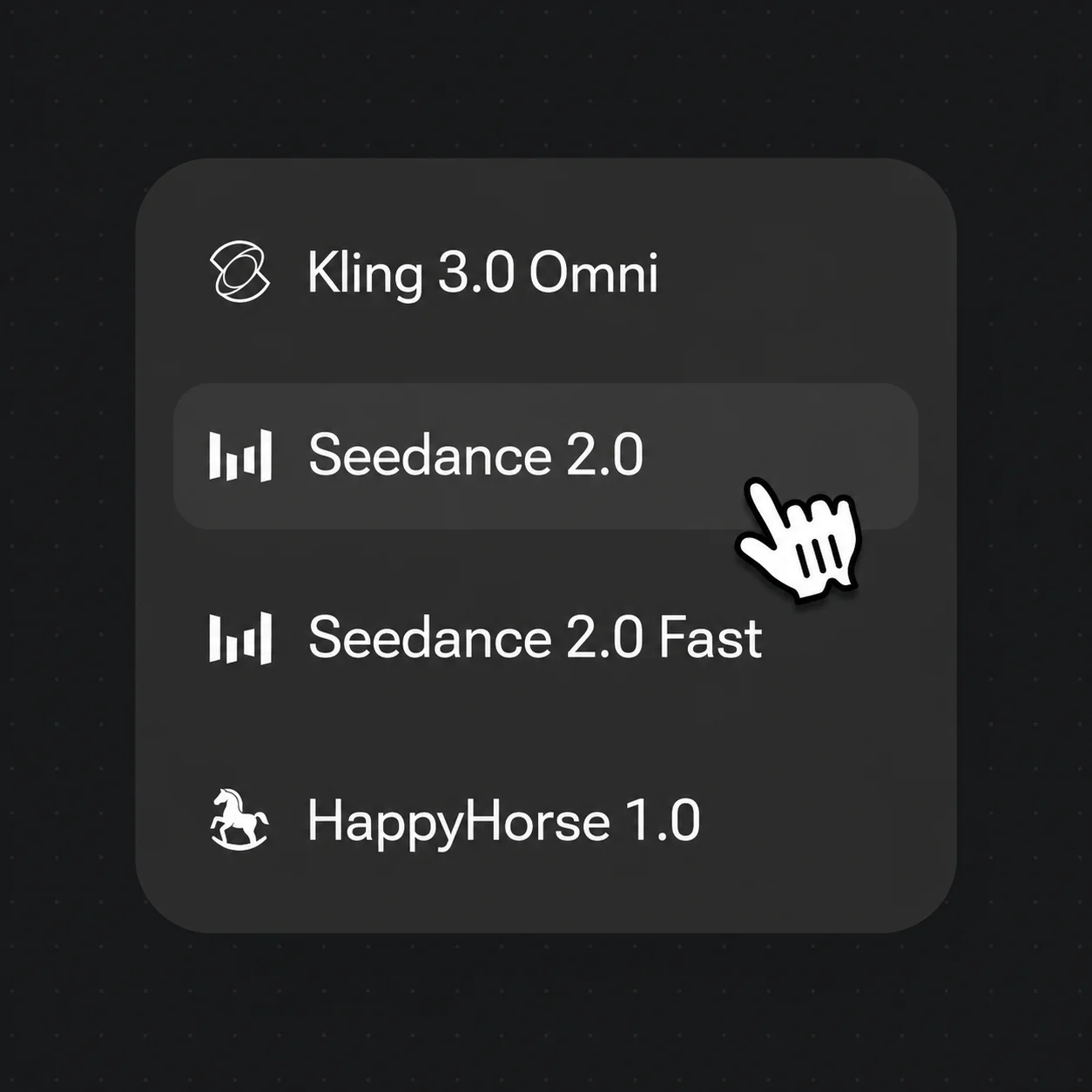
打开模型菜单,要会说话的数字人就选 Kling 3.0 Omni,要原生带音、电影感的动态就选 Seedance 2.0。
把这张肖像做 image-to-video,加一句台词用于 lipsync,再在 Canvas Timeline 上拼接片段,做成更长的作品。
Renoise 里生成人物的画面——这些是把某一帧送去做视频之前,你出发用的数字人。

对着镜头讲话的口播主持人。

一位主持人在场景中走动。

Kling 3.0 Omni 原生 lip-sync。

在同一个场景里安排多位原创人物。
两者都在同一个 Renoise Canvas 里——按镜头来选。要会说话、多镜头的数字人就用 Kling 3.0 Omni;要原生带音、电影感的动态就用 Seedance 2.0。
| 用于 AI 数字人视频 | Kling 3.0 Omni (Recommended) | Seedance 2.0 |
|---|---|---|
| 最适合 | 会说话的主持、多镜头 | 原生带音、电影感 |
| 原生 lipsync | ✓ | — |
| 多主体一致性 | ✓ | 良好 |
| 支持 FacePass | ✓ | ✓ |
| 片段时长 | 3–15 秒(带参考视频时 ≤10 秒) | 4–15 秒,另有 Fast mode |
| 分辨率 | 720p / 1080p | 720p / 1080p |
在这个领域,"AI 数字人"通常指两类东西之一。数字人是你从零生成的人物——描述脸型、年龄、造型和光线,得到一张写实肖像,再把这一帧做成视频让它动起来。AI 头像则是一套现成的说话头像,你往上套台词:更快,但那张脸是模板,不是你自己创作的。Renoise 站在数字人这一侧:人物是你生成的,所以样子是你的,而不是某个素材库里的主持人,而且你对取景、动态和场景保有完全掌控。
实际工作流是"先生成、再动起来"。先用一个图像模型锁定人物和分辨率(1K–4K),再把这一帧用视频模型做 image-to-video。需要数字人开口时就选 Kling 3.0 Omni——它的原生 lipsync 会把一句台词同步到嘴形——并能在多个镜头之间保持多主体一致性。如果数字人是在场景中走动、而非对着镜头说话,就选原生带音、有电影感的 Seedance 2.0。
当数字人是真人时,规则就变了。一张可被识别出的真人脸会被当作需要授权的肖像处理,因此必须先过 FacePass——只能是你拥有的脸,或获得书面同意的脸——才能进入视频。完全虚构、生成出来的数字人则无需授权。公众人物、名人和未成年人一律不允许。
AI 数字人视频靠的是几样东西——视频模型、肖像授权,以及 Canvas。
原生 lipsync 加多主体一致性,让一个数字人能跨镜头做主持。
从一句 prompt 出发,生成原生带音、支持多模态参考的视频,最高 1080p。
在进入视频之前,先把你拥有或获得授权的真人肖像审过。
把数字人片段拼成更长的主持视频,带剪切和转场。
一个套餐即可解锁 FacePass、Kling 3.0 Omni、Seedance 2.0 以及其余所有模型。
先生成人物的一张肖像,再把这一帧用 Kling 3.0 Omni 或 Seedance 2.0 做 image-to-video。Kling 3.0 Omni 自带 lipsync,能让数字人说话;Seedance 2.0 输出原生带音的动态。要做更长的作品,就在 Canvas Timeline 上拼接片段。
不是。本页讲的是在视频里生成逼真的 AI 数字人——一个你能让他出镜的数字人物。它不是 AI 文本 humanizer,也不是用来改写 AI 写的文字的工具。这里的"人"是你生成并让它动起来的人物。
只能用你有权使用的脸——你自己的,或获得书面同意的。真人脸必须先过 FacePass,可被识别出的真人脸在过审之前会被拦下。完全虚构、生成出来的数字人则无需授权。公众人物、名人和未成年人不允许使用。
数字人需要说话时用 Kling 3.0 Omni——它的原生 lipsync 会同步语音——或者用于多镜头一致性。要原生带音、电影感的动态就用 Seedance 2.0。两者在同一个 Canvas 里都支持 FacePass,所以你可以按镜头来回切换。
能,在 Kling 3.0 Omni 上。它的原生 lipsync 会把一句台词同步到嘴形,让生成的主持人讲出一段稿子。把台词加进 prompt,模型就会让脸部动作与之对上。
写实肖像能稳住,参考同一张源图能让样子在多个片段间保持——但一致性是模型很强的表现,并非保证,脸仍可能发生漂移。至于真人肖像,FacePass 授权是与此分开的另一回事。
Renoise 的视频模型输出 720p 或 1080p。4K 这一档只适用于你用来生成源肖像的图像模型,不适用于视频本身。要发到社交或短视频平台,用 1080p 生成即可。
