多个模型
Seedance 2.0、Kling 3.0 Omni 和 HappyHorse 1.0——无需离开 Canvas 即可挑选最合适的那一个。
在同一个 Canvas 上切换顶级视频模型——无需在多个工具间来回跳转。
Seedance 2.0、Kling 3.0 Omni 和 HappyHorse 1.0——无需离开 Canvas 即可挑选最合适的那一个。
在 Seedance 2.0 上用多达 9 张图片、3 段视频和 3 段音频参考来驱动一个镜头。
完成一次性的肖像审核后,即可把已获授权的真人面孔带入你的镜头。
在同一条时间轴上分镜、续接并拼接片段,组成完整的序列。
三者都是集成的 SOTA 模型。按时长、对口型和输入方式来选择。
| 规格 | Seedance 2.0 (Recommended) | Kling 3.0 Omni | HappyHorse 1.0 |
|---|---|---|---|
| 开发方 | ByteDance | Kuaishou | 已集成 |
| 片段时长 | 4–15s | 3–15s | 3–15s |
| 分辨率 | 720p / 1080p | 720p / 1080p | 720p / 1080p |
| 画幅比例 | 6 | 5 | 5 |
| 原生对口型 | — | ✓ | — |
| 参考视频 | ✓ (×3) | ✓ (×1) | — |
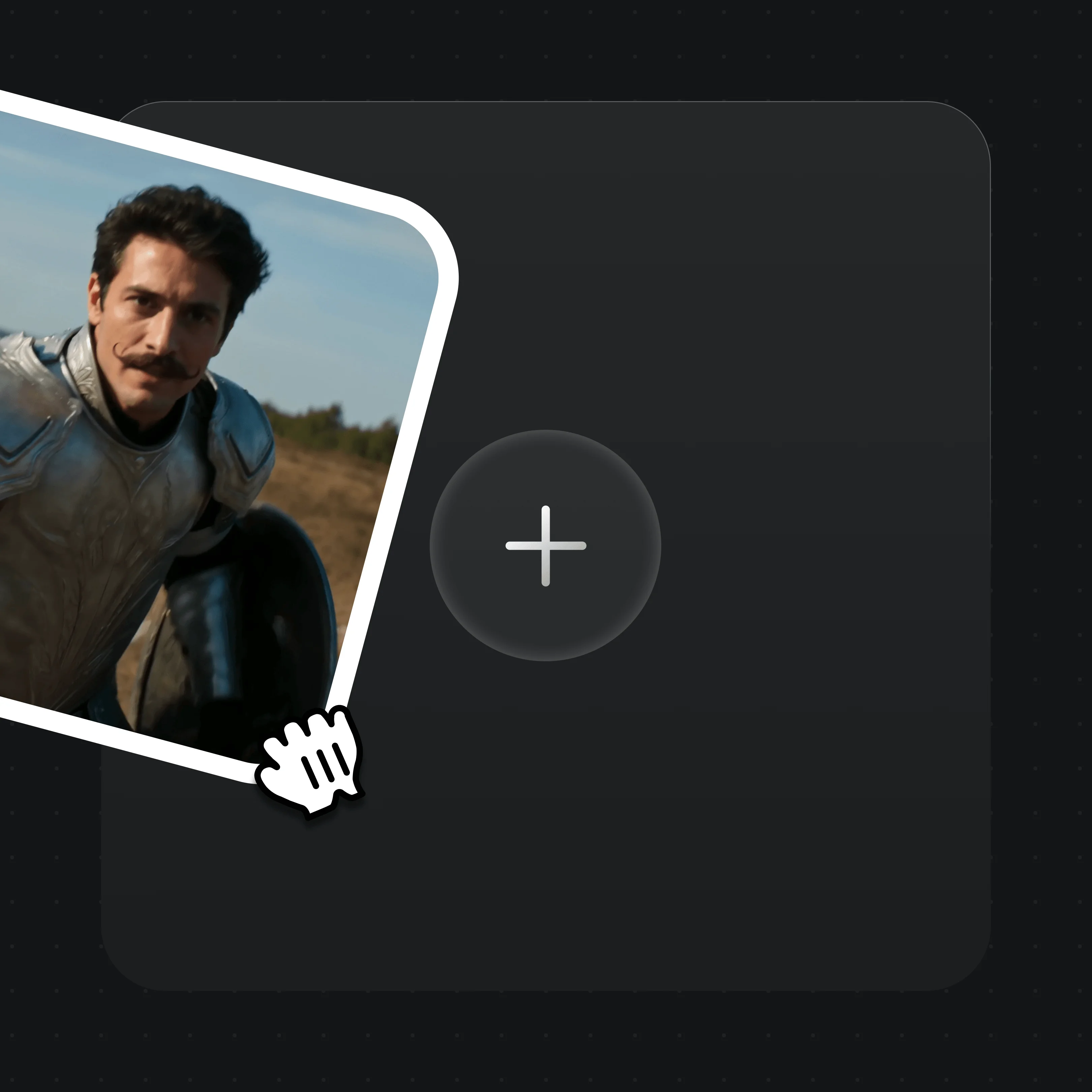
拖入参考图片、视频或音频来引导镜头——或者从零开始用提示词生成。

描述这个镜头——光线、角色、动作。一句详细的话就足够了。
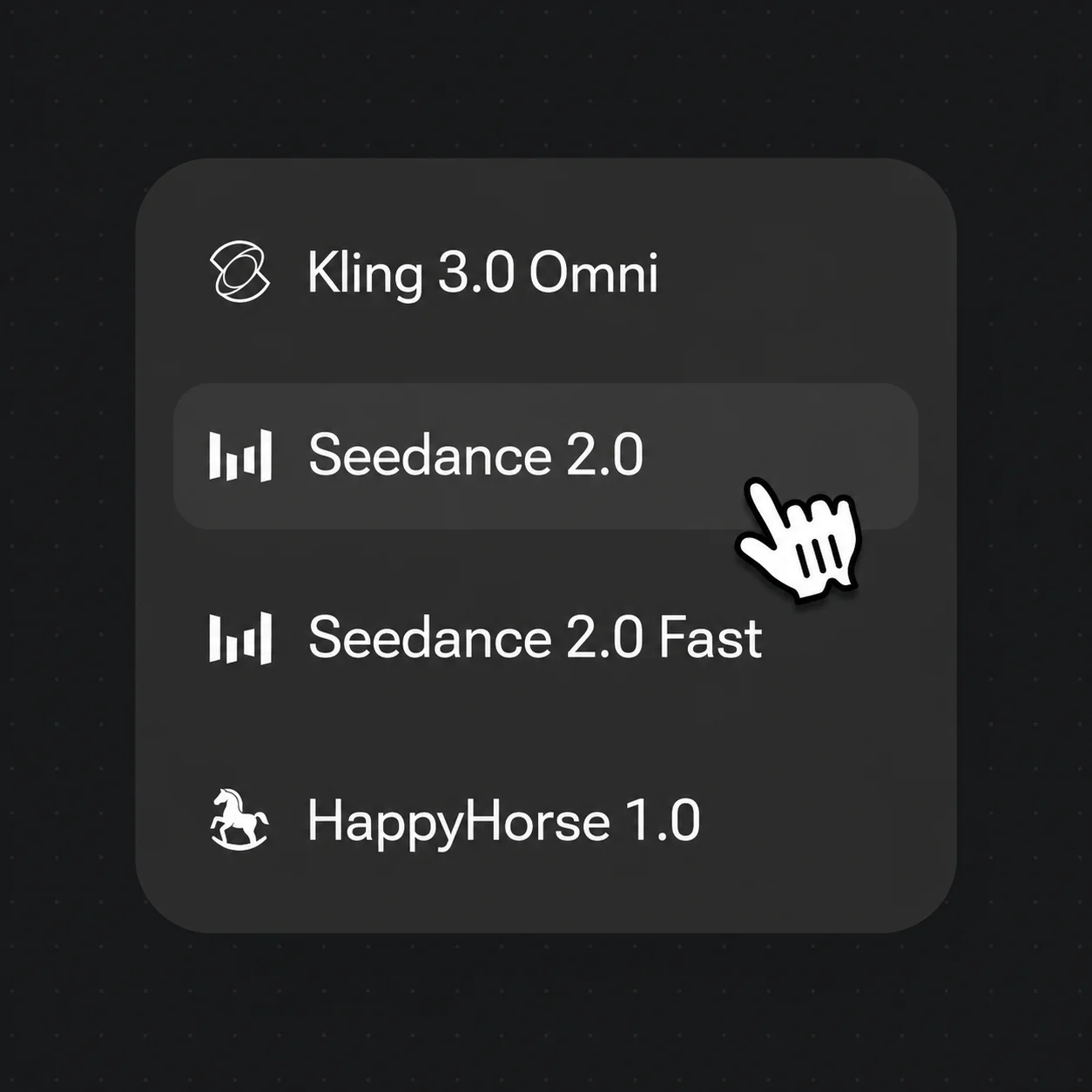
选择 Seedance 2.0、Kling 3.0 Omni 或 HappyHorse 1.0,设定 4–15s 和 720p/1080p,然后生成。
使用 Renoise 各视频模型生成的片段。
骑士对战巨龙的镜头,伴随真实的物理动态——布料、火焰,以及镜头推进。
一位厨师在明火厨房里忙碌——可信的双手、火焰与蒸汽。
一名花样滑冰运动员表演中的瞬间,以流畅的高速镜头跟拍捕捉。
驾驶舱内的太空战斗,画面中充满视差、辉光与纵深感。
一个套餐,解锁全部视频模型、FacePass 和 Canvas 时间轴。
Renoise 集成了 Seedance 2.0(ByteDance)、Kling 3.0 Omni(Kuaishou)和 HappyHorse 1.0。你可以在同一个 Canvas 上切换它们——Renoise 本身并不训练视频模型。
Kling 3.0 Omni 具备原生对口型,因此是说话角色的首选。对于一般的电影级镜头和较长的片段,Seedance 2.0 是默认推荐。
每段片段根据模型不同为 3–15 秒。若需更长的视频,可在 Canvas 时间轴上拼接多段片段——一支音乐视频通常需要 6–10 段。
不能。视频输出为 720p 或 1080p。4K 适用于图片模型(Nano Banana 2 / Pro、GPT Image 2),不适用于视频。
可以。上传一张图片作为首帧,模型便会让它动起来。Seedance 2.0 和 HappyHorse 1.0 都支持从参考图片进行图生视频。
Seedance 2.0 可以生成自带音频的片段,Kling 3.0 Omni 则会将口型与你的音频同步。Renoise 并不是独立的音乐或语音生成器。
只能通过 FacePass。模型默认会拦截真人面孔;FacePass 会在一次性审核后放行你有权使用的面孔。公众人物和未成年人不在许可范围内。