原生唇形同步
角色开口即与台词同步——唇形同步内建于模型,无需单独处理。
快手的旗舰视频模型——唇形同步、多镜头,同在一个 Canvas。
角色开口即与台词同步——唇形同步内建于模型,无需单独处理。
基于 5 种以上输入模态,让一个镜头里的多个角色保持连贯一致。
一次生成即可执导一段多镜头序列——无需拼接。
遵循物理规律的动态表现,让动作、布料和碰撞都真实可信。
拖入最多 7 张图片、1 段参考视频,或首帧/尾帧。系统自动进行 MD5 去重。

用大白话描述镜头、台词和运镜,并设置 3 到 15 秒。
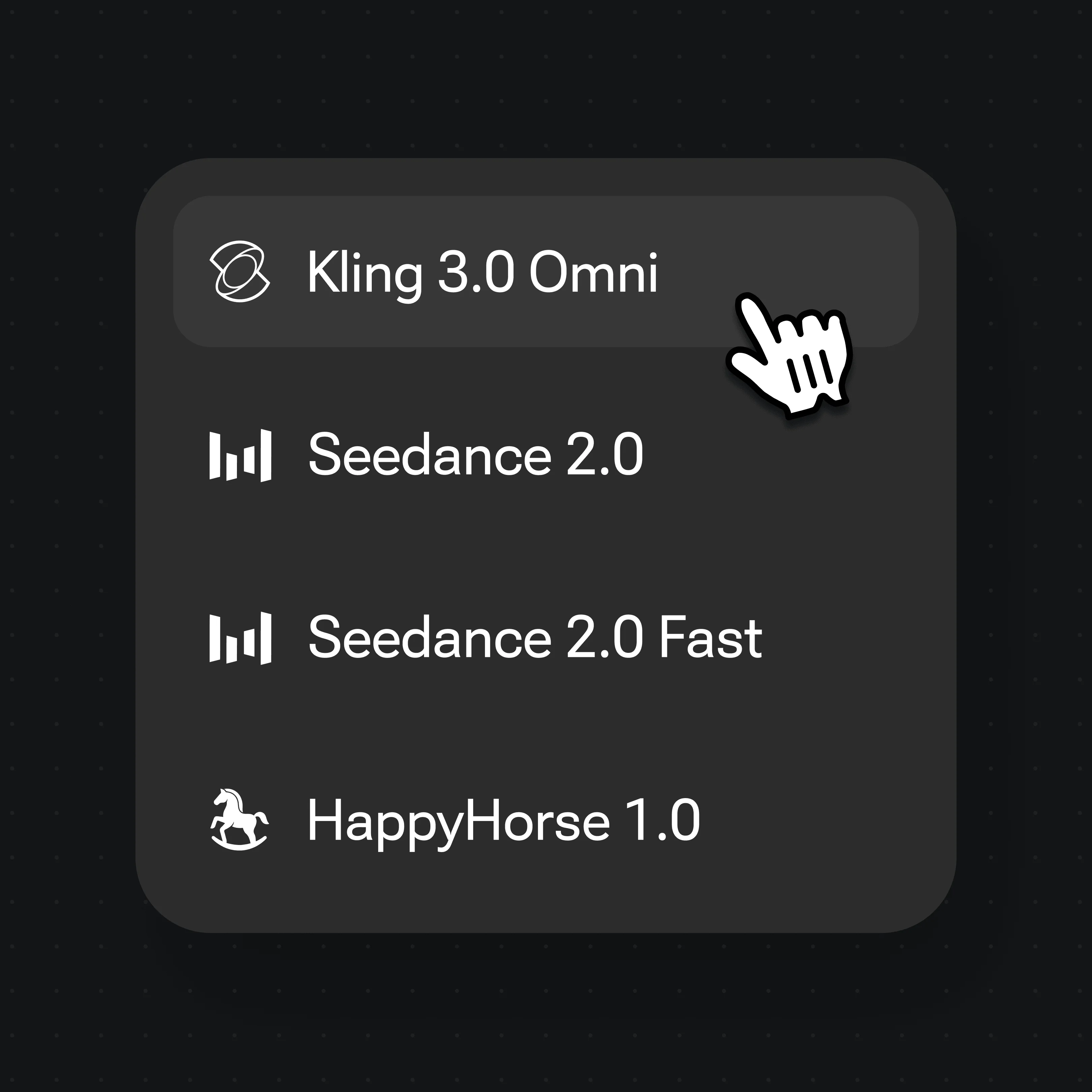
在模型选择器中选择 Kling 3.0 Omni,点击 Generate。
用一段提示词执导多个相连的镜头——Kling 3.0 Omni 单次最多可处理 6 个。
引用一张图片,让同一主体贯穿整段动态序列。
布料、发丝和碰撞都以可信的物理动态运动。
以首帧让一张静态图动起来,或用一段参考视频将其延展。
两者都在 Renoise 中运行——按镜头各取所需,没有谁更优。需要唇形同步和多镜头创作时选 Kling 3.0 Omni;需要音频原生视频和 21:9 画幅时选 Seedance 2.0。
| 看你的镜头需求 | Kling 3.0 Omni | Seedance 2.0 |
|---|---|---|
| 最适合 | 唇形同步与多镜头场景 | 音频原生、电影级 21:9 |
| 原生唇形同步 | ✓ | — |
| 单次生成多镜头 | 最多 6 个镜头 | 通过续接 |
| 画幅比例 | 5 种(16:9 至 3:4) | 6 种(含 21:9) |
| 片段时长 | 3–15s(含参考视频时 ≤10s) | 4–15s,另有 Fast 模式 |
| 参考输入 | 图片 ×7、视频 ×1 | 图片 ×9、视频 ×3、音频 ×3 |
Kling 由快手开发。Renoise 将 Kling 3.0 Omni 与 Seedance 2.0、HappyHorse 1.0、Nano Banana 2 / Pro、GPT Image 2 和 Midjourney V7 一同集成——Renoise 本身并不训练视频模型。
快手的旗舰视频模型,支持 5 种以上输入模态。它带来原生唇形同步、多主体一致性、单次生成最多 6 个镜头,以及遵循物理的动态。在 Renoise 中,它是共享 Canvas 上的一个模型。
支持。唇形同步是 Kling 3.0 Omni 的原生能力,角色无需额外步骤即可与台词同步开口。搭配 FacePass,还能用经授权的真实面孔作为参考。
每段片段为 3 到 15 秒;若包含参考视频,则最长 10 秒。如需更长的作品,可在 Canvas 时间轴上拼接多段片段。
支持。可用最多 7 张参考图片、首帧或尾帧,或 1 段参考视频来驱动镜头。Renoise 会将参考素材重新上传到其素材库,并自动进行 MD5 去重。
无法直接使用——模型会拦截可识别的真人面孔。请先通过 FacePass 验证一张你有权使用的面孔;通过后的面孔即可作为参考使用。公众人物、名人和未成年人不在许可范围内。
不能。Kling 3.0 Omni 以 720p 或 1080p 输出。4K 适用于图片模型——Nano Banana Pro 和 GPT Image 2——不适用于视频。
需要唇形同步或多镜头序列时,选 Kling 3.0 Omni;需要音频原生视频、21:9 画幅或更多参考输入时,选 Seedance 2.0。两者同在一个 Canvas,可按镜头随时切换。